The saga of microservices data management
30.10.2023
Microservices are the new reality of application architecture. They are no longer a hyped-up trend for the foreseeable future, but a modern standard for building large-scale applications. This trend is expected to persist, given the multitude of advantages it offers such as improved scalability, better fault isolation, and greater business agility.
In many cases, developers will have to migrate an already existing application, built in the traditional monolithic style, to a new system, based on microservices. Throughout this transition, one particular challenge stands out due to its complexity and significance regardless of the chosen technology: how to effectively manage data?
Data management in the context of microservices brings many questions: Shall we keep the single database approach, that is suitable for a monolith, in a distributed environment? What are the problems with this design decision, and yet which are the use cases for it? If we decide to apply the database-per-service approach – how do we manage transactions, which are no longer confined to a single database but are inherently distributed?
In this article I aim to give answers to these questions. I will focus specifically on a design pattern that is commonly used to handle distributed transactions: the Saga design pattern. Sagas, according to Google, are long stories of heroic achievement. What do they have to do with microservices? Well…
Come, aspiring digital wizards, gather 'round, and let yourselves be enchanted by the saga of Data Consistency within the labyrinth of Microservices—a tale where the integrity of data wields the power to unlock the deepest secrets of this magical world… or at least save some trouble later.
The old monolitic approach
Many applications are developed using monolithic architecture. Monoliths are self-contained applications, that encapsulate all the business concerns in a single codebase. They are the traditional way of building software applications. While they may have internal modules, they are deployed as a single entity. When more resources are needed, the whole monolith is replicated, and several instances are being run behind a load balancer. Monoliths are faster to develop, their deployment is straightforward, and are considered easy to test.
But what about the data? Most of the applications rely on a single database, meaning that all services requiring data access are in a single codebase. The database itself can come in various forms, such as relational or NoSQL, with varying data volumes, ranging from millions of records to just a few thousand. Yet, in essence, it remains a singular database.
Let's ground this abstract theory in a practical example. The project that I will be analyzing revolves around the implementation of an educational learning management system (LMS) that consists of several modules: course management, student enrollment, payment system, notification system, content delivery, assessment, and analytics module. Currently, it is a monolithic application, all these services are grouped in one big codebase with a single database. Consequently, every request, regardless of whether it is a new student enrolling for a course or homework being graded is being processed by the same codebase and stored in a single database. Throughout this article, I will be using this project as a case study to demonstrate various design approaches in the different stages of application development – from monolith to microservices.
Relying solely on a single database offers numerous benefits, including simplicity and effortless querying. However, one advantage stands out above the rest: ACID Compliance.
The ACID principles play a pivotal role in upholding data integrity and dependability within database systems. ACID is an acronym for four essential properties a transaction should possess to ensure the integrity and reliability of the data involved in the transaction.
A transaction is a series of one or more operations executed as an indivisible unit of work. This ensures that all operations are either completed entirely or rolled back in case of failure, preserving both data integrity and consistency. In this article, we will shine a spotlight on transactions, as their successful execution guarantees data consistency and integrity.
The ACID principles lived in peace…
ACID encompasses four crucial principles that ensure data validity in transactional systems:
- Atomicity: A transaction is treated as a single, atomic unit. It comprises of one or more steps that must all be executed successfully to accomplish a specific task. If any step fails, the system initiates necessary rollbacks, marking the entire action as a failure. Only when all steps within the process have been executed successfully are the results committed.
In our example: Imagine a user paying a fee for a course. For the payment to be considered successful, it must be followed by the user's enrollment in the selected course. If, for any reason, the payment fails, the student should not be enrolled in the course. Both operations—payment and course enrollment—are intertwined as one atomic unit of business activity.
- Consistency: A transaction must preserve the consistency of the underlying data. Each change made to the data must not conflict with the predefined rules.
In our example: After every transaction, the data is in a valid state. For instance, if a user changes their password, it must conform to predefined length and complexity criteria.
- Isolation: Transactions are insulated from one another, preventing interference or access to intermediate states of other transactions.
In our example: Suppose a student just enrolled in a course, and an administrator queries payment information for the same course. The student's actions should be included in the report, even if the transaction is at a point where the student is enrolled but the payment hasn't been registered. This intermediate state of course enrollment should not impact other transactions.
- Durability: Once a transaction is finalized, the changes are permanently applied to the database and remain accessible, even in the event of a system failure.
In our example: If a student successfully enrolls in a course (the transaction is committed) and a power outage interrupts, when power is restored, all changes should remain intact and fully accessible, ensuring no data loss occurs.
… until the microservices came
Cloud computing has brought to light significant issues within traditional monolithic architecture, especially efficiency-based. Even the smallest production change necessitates a complete system-wide deployment, which can lead to extensive downtime, especially in large-scale projects. Another problem is the scalability of the system: some modules receive higher traffic than others, however, to increase their computing power an instance of the whole system is required. This is a costly operation, as it requires more resources.
In our example: During a sale period many users are registering for courses. To handle the increase in user traffic, the whole system with all its modules has to be scaled. This results in scaling not only modules, that are currently in high demand (such as the course sign-in module), but also others, that are not currently targeted (such as the assessment module). This leads to suboptimal resource allocation that reflects negatively on the project cost. Another problem: if there is even a minor tweak in the content management module, an entire system redeployment becomes obligatory, despite modules like the payment module remaining untouched.
To address these issues, a new software architecture is introduced: microservices. The monolithic application is separated into smaller, independently deployable, and scalable services. These services can be implemented in different programming languages and technologies, containing only a small part of the business logic which makes them easier to rewrite and optimize.
But what about the data? In the monolithic paradigm, the solution was straightforward: one codebase, one database. But in the field of microservices, new challenges arise, due to its distributed nature. One of the main challenges is transactions: the heroes that safeguard integrity and consistency. Within a distributed system, a business logic transaction may span across the domain of different microservices and may require a join between different domains. How can a system architect deal with this complexity?
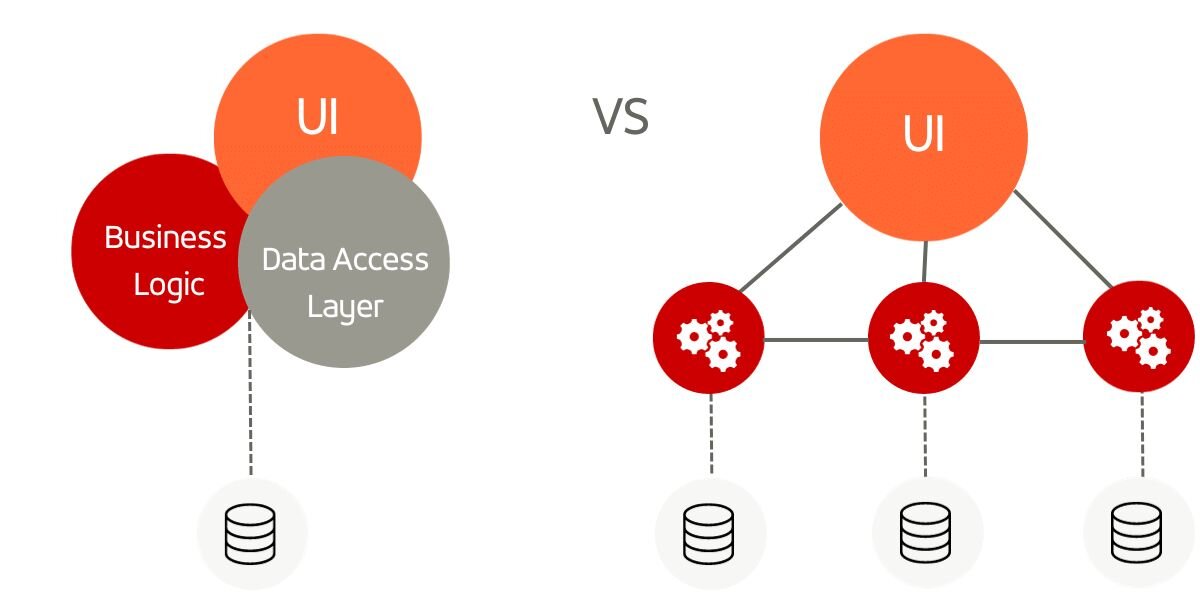
There are two paths a system can go: A shared database between services and one database per service.
Single database to store them all
One possible solution to this issue is preserving the traditional database from the monolithic approach. While the system itself is divided into microservices, they all communicate with the same database using local ACID-compliant transactions. This approach has one big advantage: it is ACID compliant, ensuring data integrity and simplifying operations by centralizing them within a single database. Even when a transaction spans across different domains, it doesn’t really affect the transaction mechanism, as it is executed on a single database. In the event of transaction failure, a rollback can easily be initiated. The simplicity of operations eliminates any concerns about data integrity and achieves the strongest consistency possible: both crucial attributes for a system.
Reality check: Single database for microservices?
Initially, a single database might appear as an excellent solution, but it carries significant drawbacks. Firstly, this approach introduces coupling on two levels. On one hand, a development time coupling: Any changes to the database should be communicated with every team, working on this solution, as they are sharing the same database, and all the entities are interconnected.
On another hand, strong coupling arises during runtime: because different services mutate the same database, longer locks may occur. Besides coupling problems, one shared database approach may be the source of scalability problems in the future. A solitary shared database might struggle to meet the data volume requirements of all communicating services and serve as a system bottleneck. Particularly, high volumes and frequent write operations can trigger a "noisy neighbor" problem.
Consider our earlier example: During the sale on our course platform, the course sign-in microservice is receiving high traffic and it is doing many modifications in the database, which require lock on different entities that are shared between the different microservices. However, when they are stored on the same database, the whole purpose of having microservices is defeated, as database transactions become the bottleneck of the system. In scenarios involving high data volumes, such as during a sale, the course sign-in microservice may frequently lock tables for extended periods, diminishing the efficiency of other microservices. As the data model is shared all entities are tightly coupled.
Use cases for shared database with microservices
Now that we've thoroughly explored the drawbacks of sharing a database among microservices, it's important to acknowledge that this approach can be advantageous in specific situations. So, when does employing a single shared database prove to be a sound solution?
The journey from monolith to microservices
The transitional period between a big old monolithic application and smaller microservices can be daunting and complex in all aspects: microservices boundaries need to be defined, and communication channels to be established. In this context, worrying about data integrity seems like a challenge in this early stage: determining how to partition the big database is a big decision that if done incorrectly can hinder the future development of the system.
This scenario presents an ideal case for the utilization of a shared database: while the system undergoes its transformation, multiple microservices can share a database. Over time, well-defined business domains will emerge, simplifying the database partitioning process.
Is this challenge worth it?
Having separate databases for every microservice is beneficial on a larger-scale project, that is facing great volumes of data and high traffic. Conversely, for systems dealing with modest data quantities or prioritizing robust consistency, the effort involved in database separation might outweigh the benefits. Synchronizing data across multiple databases introduces added complexity, that may be the turning point for smaller projects. Moreover, if the need for another database arises, changes can be made at a future point.
Database per service: divide and conquer
An alternative to the single shared database approach is the "database per service" pattern: each microservice uses its own dedicated database to persist the data, which results in multiple databases in the whole system. This configuration ensures loose coupling between microservices, meaning changes to one service's database do not impact other services, which is one of the main benefits of using microservices. Decoupling data stores has a positive effect on the resiliency of the system as it eliminates the single database as a bottleneck and single point of failure. There are different database decomposition patterns that are highlighted in this article.
The use of separate databases allows for a diverse database environment, enabling the selection of the most suitable database type (e.g., SQL or NoSQL) for each service. This flexibility extends to scalability, as individual data stores can be independently scaled to address specific needs, effectively resolving the previously mentioned problem.
In our example, this means that the payment microservice might opt for a standard SQL database, while the content management system could leverage a NoSQL database to handle data with varying structures. Each data store and microservice can be scaled independently. The different parts of the system are decoupled so changes in one don’t affect others.
This approach introduces a significant transformation in the project structure, resulting in a distributed database. It also brings forth a fundamental rule known as the CAP Theorem.
In a distributed system, it's possible to achieve only two out of three desired characteristics: consistency, availability, and partition tolerance, represented by the 'C,' 'A,' and 'P' in the name CAP. This theorem primarily addresses how a system should respond in the face of network partitioning.
Transactions in a distributed system
The distributed database approach, although beneficial for a microservices system, brings technical challenges on the data side of design: how does one handle complex transactions that span across multiple databases? How can consistency be achieved? In a single-database scenario, the answer was straightforward: the ACID principles safeguarded data integrity, and all data resided in one location, enabling easy access for all services and facilitating local transactions. However, with separate databases for each microservice, the database is no longer a singular entity; it is distributed.
There are many solutions to this problem and this article provides a quick overview of the different approaches that one could take. I will be focusing on the SAGA Pattern, as it is one of the most used strategies when dealing with distributed transactions.
A Saga of SAGA Pattern
The Saga pattern allows communication between different microservices in a transaction-like way. It defines a global transaction that spans across multiple domains as a sequence of local transactions. Each local transaction updates the service-specific database and dispatches a message or event to trigger the subsequent local transaction within the saga, creating the illusion of a single transaction, but in reality, it is a series of local ones. When a local transaction encounters a failure, either due to a constraint or business rule violation, the Saga initiates a sequence of compensatory transactions designed to revert the modifications performed by the previous local transactions.
In the context of a Learning Management System, let's consider the course signup process: the payment service confirms payment, the enrollment service registers the student for the selected course, and the notification service dispatches a confirmation email. These responsibilities are distributed across separate services: payment service, course service, and notification service; each having its own corresponding database that requires local transactions. However, those local transactions collectively form the unity of a global transaction.
How is communication managed among the various local transactions within the scope of the global one? There are two ways: Orchestration and Choreography.
An orchestrated Saga symphony
In the orchestrated Saga pattern, the main role is played by a central service that coordinates both the logic and communication between all different services involved in a certain transaction. It dictates which actions are to be executed, and their sequence. It also ensures that compensatory actions are carried out by giving both the commands for the compensation and guaranteeing that all services, that have to compensate, will execute the necessary actions.
Returning to our LMS illustration: A third service will conduct the necessary orchestration steps. It initiates contact with the course service to enroll the student, awaiting a response. Upon successful enrollment, it communicates with the payment service to confirm the payment’s success, again waiting for confirmation. Finally, it engages the notification service and awaits a success acknowledgment. If, for instance, the payment fails, a compensatory transaction intervenes, reversing the course signup and marking the entire enrollment transaction as unsuccessful.

This approach has many benefits: It provides clear visibility and ease of monitoring, as there is a central point for all the communication that happens within a transaction. This centralized control elevates data consistency to a higher level.
On the other hand, this design pattern suffers disadvantages, similar to the shared database approach: the orchestration service becomes the bottleneck of the system as it manages the traffic from and to the different systems, awaiting their responses. This approach also intensifies the coupling between services, potentially reducing system availability in the event of an orchestrator failure.
Choreographed Saga dance
Another form of the Saga pattern is the choreographed saga – it’s a decentralized model, where microservices communicate directly through events, without a central orchestrator. In this setup, services respond to events and have their own built-in compensation mechanisms. Each service maintains control over its logic, responsible for both applying actions and implementing compensatory measures.
How does this pattern apply to our LMS course signup example? Let's consider an enrollment service initiating a "New enrollment" event, which other subscribed services, including the course service, consume. The course service knows how to handle this event and can emit messages on its own signifying success or failure for the course sign-up. If there are no errors, a "Successful course sign-up" event is published, and subsequently consumed by the payment service. This microservice handles the financial aspect, emitting a "Successful payment" event if it succeeds. This event acts as a trigger for all subscribed services, such as the notification service. Each service emits and consumes events, responding autonomously, all without the need for a centralized orchestrator.
Regarding compensations, if the payment fails, the payment microservice issues a failure event. Services subscribed to this event manage their own compensatory actions and emit corresponding events for their subscribers to act upon.
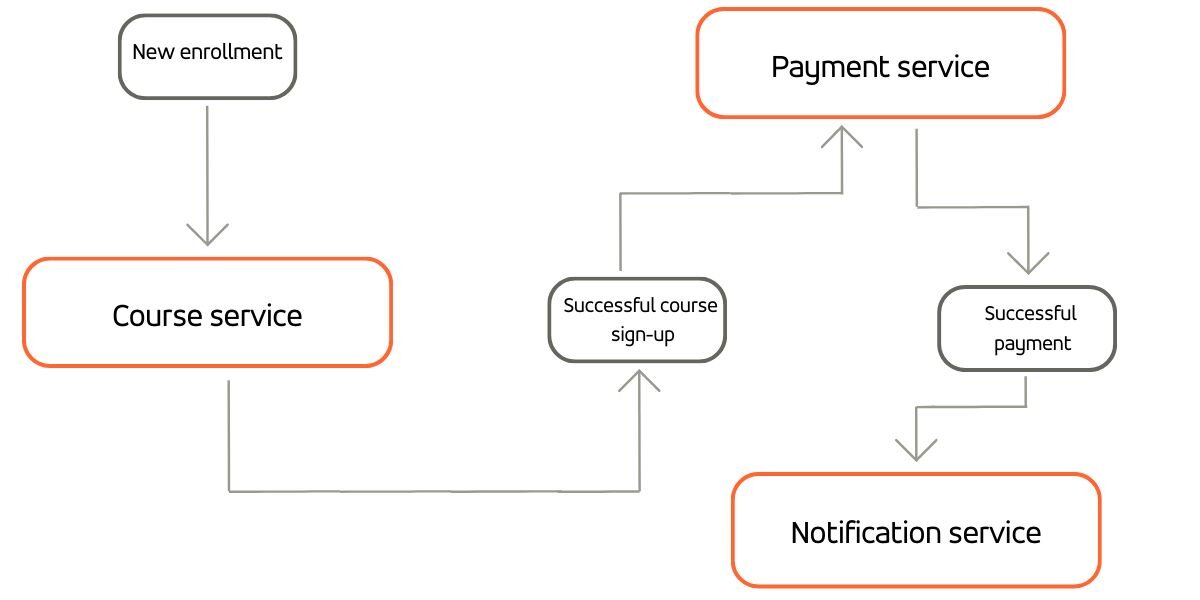
The event publishing and subscription are responsibilities of the microservices themselves, not of a global coordinator. This allows the creation of a decentralized system, promoting loose coupling among microservices, thereby enhancing system availability. Conversely, the choreography saga pattern presents challenges in testing and monitoring, introducing an added layer of complexity linked to events.: It requires constructing a shared event schema and semantics between services, along with mechanisms for handling duplicate or out-of-order events.
Choreography vs orchestration Saga: Which path should we take?
Choreography and orchestration are two distinct strategies for managing communication when transactions span among multiple microservices. Choreography prioritizes decoupling and can complicate debugging and control flow tracking, potentially leading to a less consistent system.
On the other hand, orchestration provides improved observability, debugging capabilities, scalability, and centralization, but it comes with the risk of a single point of failure and may restrict system availability.
If your system is widely distributed, demanding loose coupling (e.g., IoT), or if it already employs an event-driven architecture (e.g., chat applications), choreography is the apt choice. It enhances system availability and fault tolerance, albeit at the expense of data consistency. On the other hand, if the system requires stronger auditing and close tracking (as are most financial systems) or the transactions follow complex predefined business processes, then orchestration would be more suitable, as it provides high monitoring capabilities.
Happily ever after?
At the end of our story, the key to a happy ending lies deep within the careful and detailed system analysis. There is no universal good solution as every system is different and has unique requirements. Sometimes the development complexity of microservices is too much technical overhead, compared to the simplicity of a monolith.
In other cases, the step towards separating an existing database is too demanding in the early stage of the transition to microservices or the consistency requirements are crucial. And even if we choose the database per microservice path – the choice of distributed transaction handing technique depends on the system – does it favor availability over consistency? Analyze the system requirements and just like the heroes in sagas, you shall be triumphant.
In case you still have any questions regarding data management within the microservices environment, the team and I are one message away.