MLFlow: Capturing the ML serendipity
30.01.2023
Serendipity is defined as an unplanned fortunate discovery. But how do we capture ML serendipities? Unlike software development, building machine learning models is not a straightforward process and the daily job of data scientists and machine learning engineers consists of doing lots of experiments. We all have been there. Doing a quick-and-dirty test, or a PoC that produces awesome results, only to find out the next day that we can’t remember exactly how we achieved them. We can’t reproduce those results.
There are several ways of tracking our experiments and I’ll show some of them. My main focus will be MLFlow, a framework for organizing and tracking our modeling projects.
Setting the example
Our example will be based on the infamous Iris dataset. We train a simple logistics regression model on the training portion of the split dataset.
Cool, we have a model and some outcomes. Let’s imagine that it produced some awesome results for us, without specifying any hyperparameters or custom seeds. We run to our managers to report our success, just to find out we don’t know under what conditions these results were produced. We didn’t save that awesome model.
JupyterLab checkpoints
Jupyter Notebooks/Lab are tools to create documents with live code, visualizations, and text, called notebooks. They have the option to save a checkpoint of your current notebook. In theory, checkpoints are great: take a snapshot of the notebook and store it, in case at some point you need to revert to a previous version. In practice, I had little success with restoring work from a notebook in that way, because the functionality is limited to only a single version of the notebook. It is only created explicitly when you hit the ‘Save’ button. Also, they do not track the modeling results. A much better implementation of tracking changes is available in the Databricks platform, where each change in the notebook is tracked, and you can easily revert to it.
Enter MLFlow
MLFlow is a Python package, created by Databricks. As the authors describe it, it’s “An open-source platform for the machine learning lifecycle”. It enables an everyday machine learning practitioner to manage the lifecycle of their modeling project in one single platform. MLFlow has 4 interconnected aspects:
- MLFlow Tracking - recording experiments and runs.
- MLFlow Projects - gives us the ability to easily package our data science code into a reusable, reproducible manner. It integrates well with environment management tools like Conda, virtualenv, as well as Docker.
- MLFlow Models – a standard format for packaging the models for use in downstream applications. For example, an inference REST API, or batch processing.
- MLFlow Model Registry – full lifecycle management of a model: storing, annotating, and serving models from a central location.
How to use MLFlow to track our experiments?
Let’s pip install MLFlow and start using it:
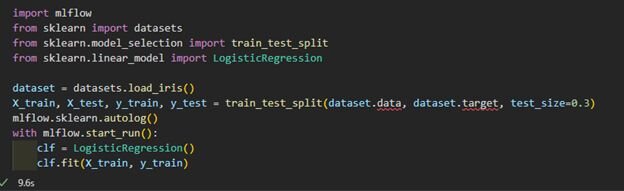
This example differs from the previous by 3 lines: the import of MLFlow, requesting it to autolog everything it knows about scikit-learn models, and then starting the run. Now each time we run this code cell, MLFlow will capture all required information and store it in the same directory under a folder named mlruns:
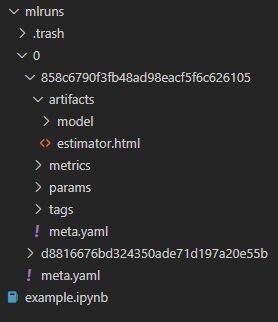
This directory contains each run for our experiment 0, and they have these unique names (858c6…, d88166…). Each run has stored everything for us: the date and time it was run, model parameters, training metrics, and artifacts.
The metrics and artifacts folders are those of most interest to us. In the former, you get the training metrics like accuracy, precision, recall, and f1. In the latter, MLFlow stores the produced model in pickle format, python_env.yaml, and requirements.txt for restoring the correct packages, as well as Conda variant in conda.yaml. In this folder, you can also find a file called MLmodel: a piece of structured information about the MLFlow project, for tracking different runs. It can be used for packaging the project and reproducing it on another system.
On average you get more than 35 files in each run’s folder. That’s a lot to be manually checking them one by one for each run. Imagine that you’d want to compare different runs. Here comes the mlflow server. When you run it in the project’s folder, MLFlow will start a webserver and it will pick up the mlruns folder. In that web app you’d be able to look at each run individually, its hyperparameters, training scores, and artifacts.
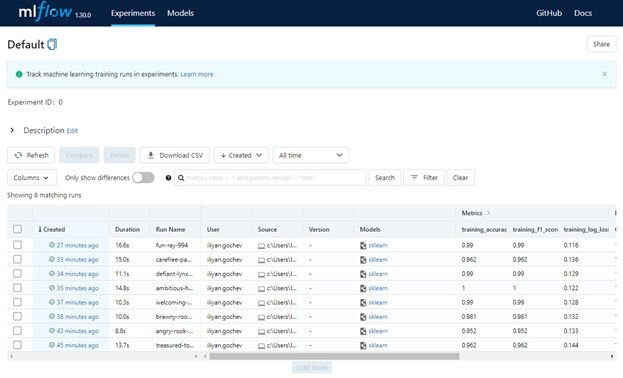
For the keen observer, you’ve seen the Compare button. You can compare two or more runs, and all of their properties to make a final decision about which model should be deployed in a production environment.
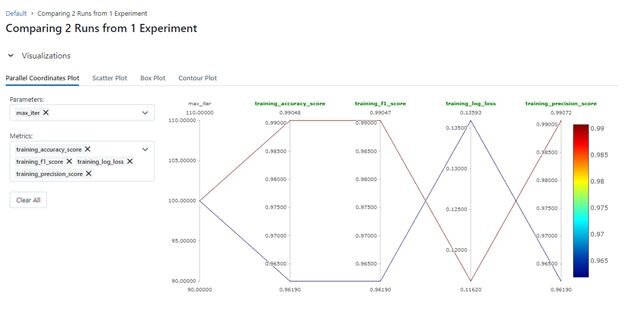
What is even better, you can have the server hosted inside your organization and have it track and compare experiments from all users of the server.
Let's automate it even further
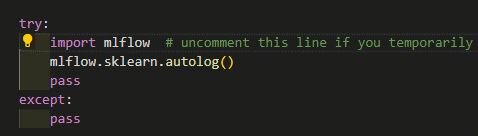
Some of you would say “That’s great but what happens if I forget to include MLflow in my project?” Here, understanding how Python’s notebooks work will help us solve this problem. Each notebook is just an interface for writing the code. Whether it is Jupyter or VS Code all code cells are executed by a Python “kernel” – the iPython command. iPython is the interactive REPL (read-evaluate-print-loop) for Python, and it offers a lot of configurability. This is what we’ll use to solve our problem. We can add a file that will load and initialize MLFlow for us every time iPython is started. Go to your home directory and if you’ve run iPython at least once you’d have a `.ipython` folder. Then go to `.ipython/profile_default/startup`. Here you can add startup files for different initializations, for example always importing specific packages or any other valid Python code. We could do something like this if we use Scikit-learn:
Now let’s run our first example, the one not annotated with MLFlow:
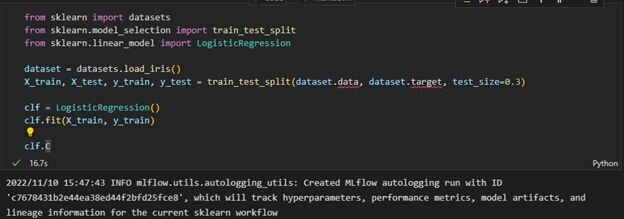
As you can see, MLFlow tracked the experiment run, even though we have not explicitly imported it and used it in our script.
To wrap up
One of the principles of MLOps is Reproducibility. The ability to accurately reproduce or re-create your experiments and model training is of utmost importance in today’s world of large-scale deployments. My request to you is to try using an experiment-tracking solution today. Whether it’s MLFlow, Weights and Biases, Nepture, or another free or paid service that comes, doesn’t really matter. Create a mental checklist (or put it on a stickie) that will remind you of your goal. Here’s the checklist, I strive to do before starting work on a project:
- Am I in the right virtual environment for the project at hand?
- Am I starting JupyterLab in the correct project directory?
My shell is always showing me this information, as well as Git status and Python version:

- If I’m using JupyterLab / VSCode / Azure ML Studio etc., I always check whether I’m using the correct kernel. A lot of times, people start a new project from an old one.
- I do a trial run just to see that my experiment tracking is working as expected.
- When I’m done with my work for the day I check the results again, and I clean up the failed experiments if I haven’t done that already.
- When the project is finished, I archive it with the experiments, if I’ve done local development.
If there’s one thing to take from this: Get into the habit of producing reliable and reproducible research and models.
Need more information and advice on making the most of your Machine Learning project? Don’t hesitate to reach out!